для чего используется визуальный ресурсный оптимизатор сдо
Что такое система дистанционного обучения (СДО) и чем она может быть вам полезна?
Система Дистанционного Обучения (СДО) – это система из информационных компонентов и процессов, которая помогает качественно обучать и обучаться на расстоянии и без очных занятий. Проще говоря, СДО – это школа, в которой рутинные и сложные процессы выполняет машина.
Существуют СДО, в которых информация передается через радио, почту или физические носители. Но в этой статье мы рассмотрим самые перспективные и часто используемые СДО – работающие с помощью электронных гаджетов и Интернета.
Если вы смутно представляете, что значит фраза «система дистанционного обучения» и какую выгоду СДО могут вам принести, данная статья даст вам ответы на вопросы.
Что такое система дистанционного обучения?
Электронные СДО – это набор информационных и технических компонентов, который создан для простой передачи знаний преподавателя ученику без необходимости очных встреч.
В нее входят и физические носители, такие как серверы, компьютеры и гаджеты, программные решения, например, LMS – системы управления обучением, сформированные заранее курсы и базы знаний, записанные на электронный носитель.
Дистанционному обучению исполнилось уже больше 300 лет, оно прошло путь от курсов, где материал и задания шли по почте в течении месяцев, до интернет-платформ, где передача информации происходит в течении считанных секунд.
Конечно, такой скачок в скорости был бы невозможен без оптимизации и систематизации процессов. Именно для этого были созданы СДО – готовые решения для повышения эффективности и простоты образования на расстоянии.
Какими бывают СДО?
Чаще всего электронные системы дистанционного обучения разделяют по двум характеристикам: по расположению системы и по цене.
По расположению системы делятся на коробочные и облачные
Коробочные СДО устанавливаются на сервер компании или учебного заведения. Доступ к ним осуществляется через Интернет или внутреннюю сеть. Такие системы обладают максимальным уровнем информационной безопасности, но при этом требуют специалиста, который будет обслуживать их, что выходит дороже для владельца.
Облачные СДО хранятся на сервере платформы, которая их предоставляет, на него же загружаются учебные материалы. Как правило, облачные СДО проще в настройке и управлении, имеют техническую поддержку, при этом создатели чаще их обновляют и вносят полезные функции и инструменты. Доступ к обучению через облачную систему может получить любой человек с гаджетом, подключенным к Интернету. Если вам важна безопасность информации, выбирайте облачную СДО с повышенным уровнем защиты.
По цене системы делятся на бесплатные и коммерческие
Бесплатные свободно распространяются в Интернете. Одной из самых знаменитых бесплатных СДО является Moodle. Но нужно учитывать, что за бесплатной оболочкой программы могут скрываться затраты на ее запуск и настройку. Например, для настройки того же самого Moodle требуются специальные технические знания, домен в Интернете, подключение базы данных и постоянное обслуживание. Эти затраты могут превысить даже стоимость среднего тарифа платной платформы.
Тем временем коммерческие СДО распространяются за деньги и чаще всего дают доступ владельцу в режиме подписки или помесячной оплаты. У них есть ряд плюсов: постоянные обновления и введение новых функций, техническая поддержка, простота в настройке и управлении, удобный доступ через компьютеры или приложения на гаджетах, хранение учебных материалов на облачном сервере.
Выбирать СДО следует с учетом целей и задач, которые она будет решать. К примеру, для запуска онлайн-школы подойдет только облачная система, если она еще качественная коммерческая, то не придется разбираться в ее настройке или тратить деньги на специалиста. А для корпоративного обучения может подойти и бесплатная коробочная, которую при должной компетенции может настроить штатный IT-специалист.
Кому будет полезно использовать СДО?
Самую большую пользу от СДО получают:
Преподаватели, которые обучают людей каким-то дисциплинам, навыкам и знаниям
Обучение через Интернет позволяет им сэкономить на аренде классов, систематизировать учебные процессы, сэкономить время и деньги на рутинной работе, повысить качество и скорость обучения. В конечном итоге любой специалист может превратить свои знания в бизнес, который будет стабильно приносить доход и поток благодарных учеников, с минимальными вложениями средств и ресурсов.
Владельцы компаний и ответственные HR-менеджеры
Использование СДО в корпоративном обучении помогает сократить расходы на него. Кроме этого система позволяет быстро и качественно обучать большие группы сотрудников по общему стандарту, автоматически проводить регулярную переаттестацию, контролировать процесс и успехи каждого отдельно взятого ученика. Современные СДО можно настроить в течении 1-3 дней без привлечения сторонних специалистов, при этом они дадут возможность вашим сотрудникам обучаться в удобное время из удобного места.
Учебные заведения
Уже многие крупные вузы перенесли часть процесса обучения в Интернет с помощью систем дистанционного обучения. Возможность пройти часть курса из дома, получить дополнительные учебные материалы или полностью изучить дисциплину повышает качество и скорость обучения студентов. А это напрямую влияет на престиж учебного заведения.
Таким образом, СДО повышают эффективность любой деятельности, в которой требуется обучать, передавать знания от одного человека другому.
Какую пользу приносит СДО в процесс обучения читайте далее.
6 задач, которые должна решать современная СДО
Качественная СДО решает минимум 5 задач в организации дистанционного обучения:
1. Организация учебного процесса
К ней относится систематизация процессов, формирование уроков, открытие к ним доступа для обучающегося в удобное для него время, планирование разных видов занятий, возможность вносить изменения и улучшения в учебные модули и другие.
2. Контакт преподавателя и студента
Он достигается через интеграцию мессенджеров в систему или с помощью встроенных видов связи: чатов, звонков, аудиосообщений, видеозвонков, конференций и других. Также он включает в себя и обратную связь, которую получает студент после выполнения и ошибок в домашнем задании.
3. Автоматический контроль знаний
Проще говоря, проверка домашних заданий. Самый простой и быстрый способ, который предоставляют СДО – это тестирование с автоматической проверкой. Если же нужен более глубокий контроль, хорошие системы дают возможность вручную проверять задание, давать подробную обратную связь или проводить экзамен в режиме реального времени.
4. Анализ усвоения материала
Сбор статистики и ее анализ помогают понять, какой модуль курса самый сложный, где нужно переработать материал для его упрощения, отслеживать промежуточные результаты обучения отдельных учеников и групп.
5. Удобный доступ к базе знаний – архиву учебных материалов
Систематизация и редактирование уже существующих уроков, добавление новых учебных материалов в разных форматах, простая работа с информацией на сервере или облаке.
6. Автоматизация доступа к курсу
СДО помогают решить трудоемкую и важную задачу – открытие доступа к курсу. Они допускают студента к занятиям в зависимости от выполнения им каких-то условий в автоматическом режиме: оплата, прохождение предыдущего урока, его должности, если это корпоративное обучение.
Одним из важных преимуществ дистанционного обучения является удобство графика и низкая стоимость. А использование специализированных систем делает такое обучение более удобным для студентов и менее затратным для владельца курса или компании, что в конечном итоге выливается в качественное обучение с одной стороны и повышение дохода с другой стороны.
Без использования систем дистанционного обучения все эти задачи администратору курса приходится решать вручную. На это тратится много времени и сил, что уменьшает эффективность работы и для преподавателя, и для студента.
Какие еще плюсы дают продвинутые СДО
Описанные выше задачи решает любая современная система дистанционного обучения. Если ее функционал не включает их, пользоваться ей невыгодно.
Но продвинутые СДО чаще всего дают своему владельцу еще больше удобных функций, которые делают обучение еще проще:
Например, через сайт или приложение, которые помогают управлять обучением и проходить курс в любом удобном месте.
Владелец СДО может создать несколько различных курсов и давать доступ студенту в зависимости от его целей.
Анализ сдачи домашних заданий и времени, проведенного в обучении, может помочь преподавателю вовремя уделить дополнительное внимание отстающему студенту.
Игрофикация и система баллов помогают поддерживать интерес к продолжению обучения и повышают количество учеников, завершивших курс.
Хорошая СДО соответствует стандарту интерактивного обучения SCORM, благодаря чему курс можно перенести с другой или на другую платформу.
СДО дают простор и удобство для обучения большого количества людей одновременно. Будут ли это учебные потоки, отдельные студенческие группы или асинхронное прохождение курса множеством людей, зависит от владельца СДО.
Коммерческие СДО могут предоставлять технических специалистов, которые помогут запустить курс обучения в течении 1-3 дней. Но это работает только с облачными СДО, потому что на запуск коробочной понадобится в разы больше времени.
Если вы обучаете за деньги, то сможете привлечь больше учеников, выбрав удобный способ оплаты для них – единовременный платеж, рассрочка, подписка или какой-то другой.
Возможность использовать функционал других крупных сервисов на платформе обучения привлекает студентов и упрощает работу владельца СДО.
Хорошие платформы дают владельцу возможность оформить их в стиле, которого придерживается его компания. Для частных онлайн-школ это тоже важно – собственный дизайн делает школу более запоминаемой.
Предприниматели, которые продают свои уроки, особенно ценят СДО, которые интегрируются с их системами управления продажами или даже предоставляют собственную.
Многие современные СДО позволяют создавать рассылки по базе учеников через емейл, мессенджеры, СМС или прозвоны. Это повышает вовлеченность студентов в обучение и помогает им не забывать о занятиях.
Этот инструмент позволяет автоматизировать продажи курсов с помощью создания лендинга, привлечения и прогрева аудитории и упрощенного способа оплаты доступа к курсу.
Некоторые СДО позволяют отслеживать статистику рекламы курса в Интернете и анализируют ее, давая владельцу понимание, какой вид продвижения и как эффективно работает для его онлайн-школы.
В зависимости от выбранной СДО и от тарифа, если она коммерческая, объем дополнительных функций варьируется. Но современные системы способны решать практически все задачи, связанные с обучением почти во всех сферах знаний.
Какие минусы есть у дистанционного обучения?
Самый большой минус дистанционного обучения – это отсутствие непосредственного контакта и контроля студента преподавателем. Тем не менее, СДО помогают если не решить эти недостатки, то сгладить их негативное воздействие.
Снижение мотивации к обучению
При отсутствии необходимости очно присутствовать на занятиях, желание закончить курс постепенно угасает у любого человека. СДО дают возможность выдавать информацию небольшими порциями, чтобы студент чувствовал постепенное движение к цели и промежуточные результаты. Кроме этого, многие современные СДО обладают системами игрофикации, поощрения и состязаний, что дополнительно мотивирует ученика.
Отсутствие эмоционального контакта
Когда обучение представляет собой только передачу информации, его качество падает из-за отсутствия эмоциональной составляющей. Качественные СДО позволяют создавать текстовые уроки, иллюстрации, видеолекции и семинары, креативные домашние задания. Кроме этого, давать личную обратную связь в удобной форме. Это не заменяет полноценных эмоций от обучения, но повышает его качество.
Низкий уровень практического обучения
Невозможность передать дистанционно практические навыки ограничивает дистанционное обучение в количестве дисциплин, которым можно обучиться с помощью него. Тем не менее, разнообразие форматов уроков, особый акцент на методическую составляющую обучения, включение очных занятий и вебинаров, использование современной техники, например, шлемов виртуальной реальности, частично решают эту проблему. Конечно, дистанционно обучать хирургов практике не сможет никто, но передать им теорию в удобном виде – запросто.
Последний минус невозможно решить с помощью СДО, ведь она и является его причиной:
Широкое использование информационных технологий требует от студента и преподавателя особые условия для обучения
К ним относятся устойчивый доступ в Интернет, технические средства для записи и просмотра уроков, определенный уровень знаний для управления процессом обучения. Проще говоря, человек без современного гаджета, умения им пользоваться и доступа в Интернет будет испытывать большие проблемы в обучении с помощью СДО.
В качестве заключения
Теперь вы в первую очередь имеете представление о современных СДО, о том, как они устроены, где применяются и как помогают улучшить процесс дистанционного обучения. Если вам этого достаточно – прекрасно, но если вам нужно больше, рекомендуем прочитать еще три абзаца.
Вы можете разобраться в СДО на конкретном примере. В статье по ссылке далее, подробно рассказано про одну из самых популярных бесплатных СДО – Moodle.
Разобравшись в СДО, вам будет полезно узнать о LMS-платформах. Они являются частью системы и отвечают за оптимизацию процессов обучения. Вы можете прочитать о них в этой статье.
Реализуем и сравниваем оптимизаторы моделей в глубоком обучении

Введение
Модель — это результат работы алгоритма машинного обучения, выполняемого на некоторых данных. Модель представляет собой то, что было изучено алгоритмом. Это «вещь», которая сохраняется после запуска алгоритма на обучающих данных и представляет собой правила, числа и любые другие структуры данных, специфичные для алгоритма и необходимые для предсказания.
Что такое оптимизатор?
Прежде чем перейти к этому, мы должны знать, что такое функция потерь. Функция потерь — это мера того, насколько хорошо ваша модель прогнозирования предсказывает ожидаемый результат (или значение). Функция потерь также называется функцией затрат (дополнительная информация здесь).
В процессе обучения мы стараемся минимизировать потери функции и обновлять параметры для повышения точности. Параметры нейронной сети — это обычно веса связей. В этом случае параметры изучаются на этапе обучения. Итак, сам алгоритм (и входные данные) настраивает эти параметры. Более подробную информацию можно найти здесь.
Таким образом, оптимизатор — это метод достижения лучших результатов, помощь в ускорении обучения. Другими словами, это алгоритм, используемый для незначительного изменения параметров, таких как веса и скорость обучения, чтобы модель работала правильно и быстро. Здесь рассмотрим базовый обзор различных используемых в глубоком обучении оптимизаторов и сделаем простую модель, чтобы понять реализацию этой модели. Я настоятельно рекомендую клонировать этот репозиторий и вносить изменения, наблюдая за моделями поведения.
Некоторые часто используемые термины:

Популярные оптимизаторы
Ниже приведены некоторые из самых популярных оптимизаторов:
1. Стохастический градиентный спуск (особенно мини-пакетный)
Мы используем один пример за раз при обучении модели (в чистом SGD) и обновления параметра. Но мы должны использовать еще один для цикла. Это займет много времени. Поэтому используем мини-пакетный SGD.
Мини-пакетный градиентный спуск стремится сбалансировать устойчивость стохастического градиентного спуска и эффективность пакетного градиентного спуска. Это наиболее распространенная реализация градиентного спуска, используемая в области глубокого обучения. В мини-пакетном SGD при обучении модели мы берем группу примеров (например, 32, 64 примера и т. д.). Такой подход работает лучше, потому что требуется единственный цикл для мини-пакетов, а не для каждого примера. Мини-пакеты выбираются случайным образом для каждой итерации, но почему? Когда мини-пакеты выбираются случайным образом, то при застревании в локальных минимумах некоторые шумные шаги могут привести к выходу из этих минимумов. Зачем нам этот оптимизатор?
Каким будет формат модели?
Я даю обзор модели на случай, если вы новичок в глубоком обучении. Она выглядит примерно так:
На следующем рисунке видно, в SGD присутствуют огромные колебания. Вертикальное движение не обязательно: мы хотим движения только горизонтально. Если уменьшить вертикальное движение и увеличить горизонтальное, модель будет учиться быстрее, согласны?
Как минимизировать нежелательные колебания? Следующие оптимизаторы минимизируют их и помогают ускорить обучение.
2. Оптимизатор импульса
В SGD или градиентном спуске много колебаний. Нужно двигаться вперед, а не вверх-вниз. Мы должны увеличить скорость обучения модели в правильном направлении, и мы сделаем это с помощью оптимизатора импульса.
Как видно на рисунке выше, зеленая цветовая линия оптимизатора импульса быстрее других. Важность быстрого обучения можно увидеть, когда у вас большие наборы данных и много итераций. Как внедрить этот оптимизатор?
Нормально значение β около 0,9
Видно, что мы создали два параметра — vdW, и vdb — из параметров обратного распространения. Рассмотрим значение β = 0.9, тогда уравнения приобретает вид:
Как вы видите, vdw больше зависит от предыдущего значения vdw, а не dw. Когда визуализация — это график, можно увидеть, что оптимизатор импульса учитывает прошлые градиенты, чтобы сгладить обновление. Вот почему возможно минимизировать колебания. Когда мы использовали SGD, пройденный мини-пакетным градиентным спуском путь колебался в сторону конвергенции. Оптимизатор импульса помогает уменьшить эти колебания.
3. Среднеквадратичное распространение
Среднеквадратичное распространение корня (RMSprop) — это экспоненциально затухающее среднее значение. Существенным свойством RMSprop является то, что вы не ограничены только суммой прошлых градиентов, но вы более ограничены градиентами последних временных шагов. RMSprop вносит свой вклад в экспоненциально затухающее среднее значение прошлых «квадратичных градиентов». В RMSProp мы пытаемся уменьшить вертикальное движение, используя среднее значение, потому что они суммируются приблизительно до 0, принимая среднее значение. RMSprop предоставляет среднее значение для обновления.
Посмотрите на приведенный ниже код. Это даст вам базовое представление о том, как внедрить этот оптимизатор. Все то же самое, что и с SGD, мы должны изменить функцию обновления.
4. Оптимизатор Adam
Adam — один из самых эффективных алгоритмов оптимизации в обучении нейронных сетей. Он сочетает в себе идеи RMSProp и оптимизатора импульса. Вместо того чтобы адаптировать скорость обучения параметров на основе среднего первого момента (среднего значения), как в RMSProp, Adam также использует среднее значение вторых моментов градиентов. В частности, алгоритм вычисляет экспоненциальное скользящее среднее градиента и квадратичный градиент, а параметры beta1 и beta2 управляют скоростью затухания этих скользящих средних. Каким образом?
Гиперпараметры
Давайте построим модель и посмотрим, как гиперпараметры ускоряют обучение
Давайте начнем!
Я создаю обобщенную модельную функцию, работающую для всех обсуждаемых здесь оптимизаторов.
1. Инициализация:
Мы инициализируем параметры с помощью функции инициализации, которая принимает входные данные, такие как features_size (в нашем случае 12288) и скрытый массив размеров (мы использовали [100,1]) и данный вывод как параметры инициализации. Существует другой метод инициализации. Я призываю прочитать эту статью.
2. Прямое распространение:
В этой функции входные данные — это X, а также параметры, протяженность скрытых слоев и отсев, которые используются в технике отсева.
Я установил значение 1, так что никакого эффекта на тренировке не будет видно. Если ваша модель переобучена, то вы можете установить другое значение. Я применяю отсев только на четных слоях.
3. Обратное распространение:
Здесь мы пишем функцию обратного распространения. Она вернет grad (наклон). Мы используем grad при обновлении параметров, (если вы об этом не знаете). Рекомендую прочитать эту статью.
Мы уже видели функцию обновления оптимизаторов, так что используем ее здесь. Внесем небольшие изменения в функцию модели из обсуждения SGD.
Обучение с мини-пакетами
Вывод при подходе с мини-пакетами:
Обучение с оптимизатором импульса
Вывод оптимизатора импульса:
Тренировка с RMSprop
Тренировка с Adam
Вы видели разницу в точности между ними? Мы использовали те же параметры инициализации, ту же скорость обучения и то же количество итераций; отличается только оптимизатор, но посмотрите на результат!
Графическая визуализация модели
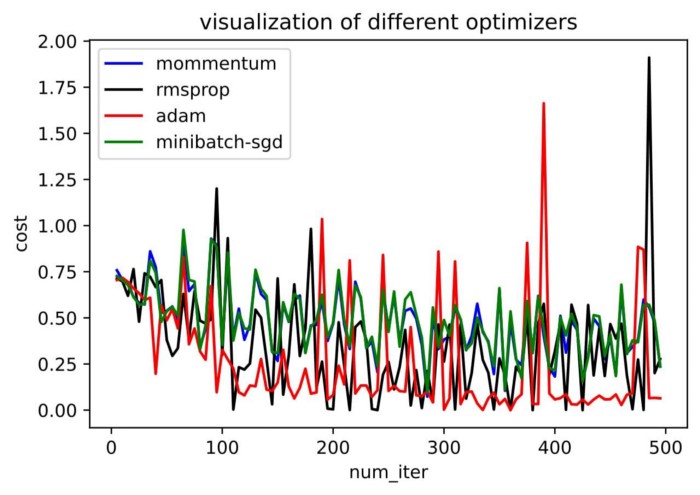
Вы можете обратиться в репозиторий, если у вас есть сомнения по поводу кода.
Резюме
источник
Как мы уже видели, оптимизатор Adam дает хорошую точность по сравнению с другими оптимизаторами. На рисунке выше видно, как модель учится на итерациях. Momentum дает скорость SGD, а RMSProp дает экспоненциальное среднее значение веса для обновленных параметров. Мы использовали меньше данных в приведенной выше модели, но мы увидим больше преимуществ оптимизаторов при работе с большими наборами данных и многими итерациями. Мы обсудили основную идею оптимизаторов, и я надеюсь, что это даст вам некоторую мотивацию узнать больше об оптимизаторах и использовать их!
Перспективы нейронных сетей и глубокого машинного обучения просто огромны, и по самым скромным оценкам, их влияние на мир будет примерно таким же, как влияние электричества на промышленность в XIX веке. Те специалисты, которые оценят эти перспективы раньше всех, имеют все шансы стать во главе прогресса. Для таких людей мы сделали промокод HABR, который дает дополнительные 10% к скидке на обучение, указанной на баннере.
Объясняем на пальцах принцип действия оптимизаторов для нейронных сетей: основные алгоритмы, и зачем они нужны
Оптимизаторы — важный компонент архитектуры нейронных сетей. Они играют важную роль в процессе тренировки нейронных сетей, помогая им делать всё более точные прогнозы. Специально к старту нового потока расширенного курса по машинному и глубокому обучению, делимся с вами простым описанием основных методик, используемых оптимизаторами градиентного спуска, такими как SGD, Momentum, RMSProp, Adam и др.
Оптимизаторы определяют оптимальный набор параметров модели, таких как вес и смещение, чтобы при решении конкретной задачи модель выдавала наилучшие результаты.
Самой распространённой техникой оптимизации, используемой большинством нейронных сетей, является алгоритм градиентного спуска.
Большинство популярных библиотек глубокого обучения, например PyTorch и Keras, имеют множество встроенных оптимизаторов, базирующихся на использовании алгоритма градиентного спуска, например SGD, Adadelta, Adagrad, RMSProp, Adam и пр.
Но почему алгоритмов оптимизации так много? Как выбрать из них правильный?
В документации к каждому из таких оптимизаторов приводится формула, с помощью которой такие оптимизаторы обновляют параметры модели. Что же означает каждая формула, и в чём её смысл?
Хочу уточнить, что данная статья написана для того, чтобы вы поняли общую картину и как в такую картину вписывается каждый алгоритм. Я не буду здесь погружаться в глубинные смыслы самих формул, так как рассуждать о математических тонкостях лучше всего в отдельной статье.
Обзор методов оптимизации на базе алгоритма градиентного спуска
Кривая потерь
Начнём с того, что рассмотрим на 3D-изображении, как работает стандартный алгоритм градиентного спуска.
Кривая потерь для алгоритма градиентного спуска
На рисунке показана сеть с двумя весовыми параметрами:
На горизонтальной плоскости размещаются две оси для весов w1 и w2, соответственно.
На вертикальной оси откладываются значения потерь для каждого сочетания весов.
Другими словами, форма кривой является отражением “ландшафта потерь” в нейронной сети. Кривая представляет потери для различных значений весов при сохранении неизменным фиксированного набора входных данных.
Синяя линия соответствует траектории алгоритма градиентного спуска при оптимизации:
Работа алгоритма начинается с выбора некоторых случайных значений обоих весов и вычисления значения потери.
После каждой итерации весовые значения будут обновляться (в результате чего, как можно надеяться, снизится потеря), и алгоритм будет перемещаться вдоль кривой к следующей (более нижней) точке.
В конечном итоге алгоритм достигает цели, то есть приходит в нижнюю точку кривой — в точку с самым низким значением потерь.
Вычисление градиента
Алгоритм обновляет значения весов, основываясь на значениях градиента кривой потерь в данной точке, и на параметре скорости обучения.
Обновление параметра градиентного спуска
Градиент измеряет уклон и рассчитывается как значение изменения в вертикальном направлении (dL), поделённое на значение изменения горизонтальном направлении (dW). Другими словами, для крутых уклонов значение градиента большое, для пологих — маленькое.
Вычисление градиента
Практическое применение алгоритма градиентного спуска
Визуальное представление кривых потерь весьма полезно для понимания сути работы алгоритма градиентного спуска. Однако нужно помнить, что описываемый сценарий скорее идеален, чем реален.
Во-первых, на приведённом выше рисунке кривая потерь идёт идеально плавно. На самом деле горбов и впадин на ней гораздо больше, чем плавных мест.
Во-вторых, мы будем работать не с двумя параметрами, а с гораздо большим их числом. Параметров может быть десятки или даже сотни миллионов, их просто невозможно визуализировать и представить даже мысленно.
На каждой итерации алгоритм градиентного спуска работает, «озираясь по всем направлениям, находя самый перспективный уклон, по которому можно спуститься вниз». Но что произойдёт, если алгоритм выберет лучший, по его мнению, уклон, но это будет не лучшее направление? Что делать, если:
Ландшафт круто уходит вниз в одном направлении, но, чтобы попасть в самую нижнюю точку, нужно двигаться в направлении с меньшими изменениями высоты?
Весь ландшафт представляется алгоритму плоским во всех направлениях?
Алгоритм попадает в глубокую канаву? Как ему оттуда выбраться?
Давайте рассмотрим несколько примеров кривых, перемещение по которым может создавать трудности.
Трудности при оптимизации градиентного спуска
Локальные минимумы
На стандартной кривой потерь, кроме глобального минимума, может встретиться множество локальных минимумов. Главной задачей алгоритма градиентного спуска, как следует из его названия, является спуск всё ниже и ниже. Но, стоит ему спуститься до локального минимума — и подняться оттуда наверх часто становится непосильной задачей. Алгоритм может просто застрять в локальном минимуме, так и не попав на глобальный минимум.
Локальный минимум и глобальный минимум
Седловые точки
Ещё одной важной проблемой является прохождение алгоритмом «седловых точек». Седловой называют точку, в которой в одном направлении, соответствующем одному параметру, кривая находится на локальном минимуме; во втором же направлении, соответствующем другому параметру, кривая находится на локальном максимуме.
Седловая точка
Какую опасность таят в себе седловые точки, которые алгоритм может встретить на своём пути? Опасность в том, что область, непосредственно окружающая седловую точку, как правило, довольно плоская, она напоминает плато. Плоская область означает практически нулевые градиенты. Оптимизатор начинает колебаться (осциллировать) вокруг седловой точки в направлении первого параметра, не “догадываясь” спуститься вниз по уклону в направлении второго параметра.
Алгоритм градиентного спуска при этом ошибочно полагает, что минимум им найден.
Овраги
Ещё одна головная боль алгоритма градиентного спуска — пересечение оврагов. Овраг — это протяжённая узкая долина, имеющая крутой уклон в одном направлении (т.е. по сторонам долины) и плавный уклон в другом (т.е. вдоль долины). Довольно часто овраг приводит к минимуму. Поскольку навигация по такой форме кривой затруднена, такую кривую часто называют патологическим искривлением (Pathological Curvature).
Овраги
Представьте узкую речную долину, плавно спускающуюся с холмов и простирающуюся вниз до озера. Вам нужно быстро спуститься вниз по реке, туда, где пролегает долина. Но алгоритм градиентного спуска вполне может начать движение, отталкиваясь попеременно от сторон долины, при этом движение вниз по направлению реки будет весьма медленным.
Алгоритм ванильного градиентного спуска, несмотря на его недостатки, по-прежнему считается основным, в частности, по той причине, что существуют специальные методы его оптимизации.
Первое улучшение алгоритма градиентного спуска — стохастический градиентный спуск (SGD)
Под обычным градиентным спуском (по умолчанию) обычно понимается «градиентный спуск со сменой коэффициентов после обсчёта всей выборки», то есть потери и градиент рассчитываются с использованием всех элементов набора данных.
Также применяется промежуточный стохастический градиентный спуск с мини-пакетами — вариант, при котором коэффициенты меняются после обсчета N элементов выборки, то есть для каждой тренировочной итерации алгоритм выбирает случайное подмножество набора данных.
Случайность выбора хороша тем, что она помогает глубже исследовать ландшафт потерь.
Ранее мы говорили, что кривая потерь получается за счёт изменения параметров модели с сохранением фиксированного набора входных данных. Однако если начать изменять входные данные, выбирая различные данные в каждом мини-пакете, значения потерь и градиентов также будут меняться. Другими словами, изменяя набор входных данных, для каждого мини-пакета мы получим собственную кривую потерь, которая немного отличается от других.
То есть, даже если алгоритм застрянет на каком-либо месте ландшафта в одном мини-пакете, можно будет запустить другой мини-пакет с другим ландшафтом, и вполне вероятно, что алгоритм сможет двигаться дальше. Данная техника предотвращает застревание алгоритма на определённых участках ландшафта, особенно на ранних этапах тренировки.
Второе усовершенствование алгоритма градиентного спуска — накопление импульса (Momentum)
Динамическая корректировка количества обновлений
Один из интересных аспектов алгоритма градиентного спуска связан с его поведением на крутых уклонах. Так как градиент на крутых уклонах большой, алгоритм в этих местах может делать большие шаги, между тем, именно здесь вы на самом деле хотите перемещаться медленно и осторожно. Это может привести к тому, что алгоритм будет «скакать» назад и вперёд, замедляя тем самым процесс тренировки.
В идеале частоту обновлений хочется изменять динамически, чтобы алгоритм мог подстраиваться под изменения окружающего ландшафта. Если уклон очень крутой, алгоритм должен притормаживать. Если склон довольно пологий, скорость вполне можно повысить, и так далее.
Алгоритм градиентного спуска обновляет веса на каждом шаге, используя в качестве параметров значения градиента и скорости обучения. Таким образом, для изменения количества обновлений можно выполнить два действия:
Скорректировать значение скорости обучения.
SGD с функцией накопления импульса и обычный SGD
Первое действие, то есть корректировка градиента, выполняется с помощью функции накопления импульса.
В SGD учитывается только текущее значение градиента, а значения всех прошлых градиентов игнорируются. Это означает, что, если алгоритм внезапно натолкнётся на аномалию на кривой потерь, он может пойти не по нужной траектории.
С другой стороны, при использовании SGD с накоплением импульса учитываются значения прошлых градиентов, общее направление сохраняется, и траектория остаётся правильной. Это позволяет использовать знания об окружающем ландшафте, полученные алгоритмом до того, как он добрался до данной точки, и смягчить эффект аномалии кривой потерь.
Сразу встаёт вопрос — как далеко можно углубляться в прошлое? Чем глубже мы погрузимся в прошлое, тем меньше вероятность воздействия аномалий на конечный результат.
И второй вопрос — все ли градиенты из прошлого можно расценивать одинаково? Вполне логично рассудить, что вещи из недавнего прошлого должны иметь более высокую значимость, чем вещи из далёкого прошлого. Поэтому, если изменение ландшафта представляет собой не аномалию, а естественное структурное изменение, на такие изменения нужно реагировать соответственно и менять курс постепенно.
Функция накопления импульса использует при работе экспоненциальное скользящее среднее, а не текущее значение градиента.
Переходы через овраги с помощью функции накопления импульса
Функция накопления импульса помогает решить проблему узкого оврага с патологическим искривлением, градиент которого, с одной стороны, очень большой для одного весового параметра, а, с другой стороны, очень маленький для другого параметра.
Функция накопления импульса помогает преодолевать овраги
С помощью функции накопления импульса можно сгладить зигзагообразные скачки алгоритма SGD.
Для первого параметра с крутым уклоном большое значение градиента приведёт к резкому повороту от одной стороны оврага к другой. Однако на следующем шаге такое перемещение будет скомпенсировано резким поворотом в обратном направлении.
Если же взять другой параметр, мелкие обновления на первом шаге будут усиливаться мелкими обновлениями на втором шаге, так как эти обновления имеют то же направление. И именно такое направление вдоль оврага будет направлением, в котором необходимо двигаться алгоритму.
Вот некоторые примеры алгоритмов оптимизации, использующих функцию накопления импульса в разных формулах:
SGD с накоплением импульса
Ускоренный градиент Нестерова
Третье усовершенствование алгоритма градиентного спуска — изменение скорости обучения (на базе значения градиента)
Как уже было сказано выше, вторым способом изменения количества обновлений параметров является изменение скорости обучения.
До сих пор на разных итерациях мы сохраняли скорость обучения постоянной. Кроме того, при обновлении градиентов для всех параметров использовалось одно и то же значение скорости обучения.
Однако, как мы уже убедились, градиенты с различными параметрами могут довольно ощутимо отличаться друг от друга. Один параметр может иметь крутой уклон, а другой — пологий.
Мы можем использовать это обстоятельство, чтобы адаптировать скорость обучения к каждому параметру. Чтобы выбрать скорость обучения для данного параметра, мы можем обратиться к прошлым градиентам (для каждого параметра отдельно).
Данная функциональность реализована в нескольких алгоритмах оптимизации, использующих разные, но похожие методы, например Adagrad, Adadelta, RMS Prop.
Например, метод Adagrad возводит в квадрат значения прошлых градиентов и суммирует их в равных весовых пропорциях. Метод RMSProp также возводит в квадрат значения прошлых градиентов, но приводит их к экспоненциальному скользящему среднему, тем самым придавая более высокую значимость последним по времени градиентам.
После возведения градиентов в квадрат все они становятся положительными, то есть получают одно и то же направление. Таким образом, перестаёт действовать эффект, проявляющийся при применении функции накопления импульса (градиенты имеют противоположные направления).
Это означает, что для параметра с крутым уклоном значения градиентов будут большими, и возведение таких значений в квадрат даст ещё большее и всегда положительное значение, поэтому такие градиенты быстро накапливаются. Для погашения данного эффекта алгоритм рассчитывает скорость обучения посредством деления накопленных квадратов градиентов на коэффициент с большим значением. За счет этого алгоритм “притормаживает” на крутых уклонах.
Рассуждая аналогично, если уклоны небольшие, накопления также будут небольшими, поэтому при вычислении скорости обучения алгоритм разделит накопленные квадраты градиентов на коэффициент с меньшим значением. Таким образом, скорость обучения на пологих склонах будет увеличена.
Некоторые алгоритмы оптимизации используют сразу оба подхода — изменяют скорость обучения, как это описано выше, и меняют градиент с помощью функции накопления импульса. Так поступает, например, алгоритм Adam и его многочисленные варианты, а также алгоритм LAMB.
Четвёртое усовершенствование алгоритма градиентного спуска — изменение скорости обучения (на базе тренировочной выборки)
В предыдущем разделе скорость обучения менялась на основе градиентов параметров. Плюс к этому, мы можем менять скорость обучения в зависимости от того, как продвигается процесс тренировки. Скорость обучения устанавливается в зависимости от эпохи тренировочного процесса и не зависит от параметров модели в данной точке.
На самом деле эту задачу выполняет не оптимизатор, а особый компонент нейронной сети, называемый планировщиком. Я упоминаю здесь об этом только для полноты картины и для того, чтобы показать связь с техниками оптимизации, о которых мы здесь говорили. Саму же эту тему логично осветить в отдельной статье.
Заключение
Мы ознакомились с основными приёмами, используемыми методиками оптимизации на базе алгоритма градиентного спуска, рассмотрели причины их использования и взаимосвязи друг с другом. Представленная информация позволит лучше понять принцип действия многих специфических алгоритмов оптимизации. А если вы хотите получить больше знаний — обратите внимание на наш расширенный курс по машинному и глубокому обучению, в рамках которого вы научитесь строить собственные нейронные нейронные сети и решать различные задачи с их помощью.
Узнайте, как прокачаться и в других специальностях или освоить их с нуля: