для чего при разработке искусственного интеллекта используются базы данных
Искусственный интеллект: краткая история, развитие, перспективы

Сейчас технологии развиваются с немыслимой скоростью. Ранее те возможности, что, казалось бы, были доступны только профессиональным ученым, в современной жизни доступны каждому. Один из подобных прорывов – искусственный интеллект, прочно обосновавшийся во многих сферах человеческой жизни.
Сегодня поговорим о том, что такое ИИ, как он возник, где применяется, а также чем он отличается от человеческого разума.
Что представляет собой искусственный интеллект
Искусственный интеллект – это свойство интеллектуальной системы выполнять те функции и задачи, которые обычно характерны для разумных существ. Это может быть проявление каких-то творческих способностей, склонность к рассуждению, обобщение, обучение на основании полученного ранее опыта и так далее.

Его развитием занимается направление науки, в рамках которого происходит аппаратное или программное моделирование тех задач человеческой деятельности, что считаются интеллектуальными. Еще под ИИ часто подразумевают направление в IT, основной целью которого является воссоздание разумных действий и рассуждений с помощью компьютерных систем.
История возникновения и развития искусственного интеллекта
Впервые термин artificial intelligence (с английского переводится как «искусственный интеллект») был упомянут в 1956 году Джоном МакКарти, основателем функционального программирования и изобретателем языка Lisp, на конференции в Университете Дартмута.
Однако сама идея подобной системы была сформирована в 1935 году Аланом Тьюрингом. Ученый дал описание абстрактной вычислительной машине, состоящей из безграничной памяти и сканера, перемещающегося вперед и назад по памяти. Однако позднее, в 1950 году, он предложил считать интеллектуальными те системы, которые в общении не будут отличаться от человека.
Тогда же Тьюринг разработал эмпирический тест для оценки машинного интеллекта. Он показывает, насколько искусственная система продвинулась в обучении общению и удастся ли ей выдать себя за человека.
Самая ранняя успешная программа искусственного интеллекта была создана Кристофером Стрейчи в 1951 году. А уже в 1952 году она играла в шашки с человеком и удивляла зрителей своими способностями предсказывать ходы. По этому поводу в 1953 году Тьюринг опубликовал статью о шахматном программировании.

В 1965 году специалист Массачусетского технологического университета Джозеф Вайценбаум разработал программу «Элиза», которая ныне считается прообразом современной Siri. В 1973 году была изобретена «Стэндфордская тележка», первый беспилотный автомобиль, контролируемый компьютером. К концу 1970-х интерес к ИИ начал спадать.
Новое развитие искусственный интеллект получил в середине 1990-х. Самый известный пример – суперкомпьютер IBM Deep Blue, который в 1997 году обыграл в шахматы чемпиона мира Гарри Каспарова. Сегодня подобные сети развиваются очень быстро за счет цифровизации информации, увеличения ее оборота и объема. Машины довольно быстро анализируют информацию и обучаются, впоследствии они действительно приобретают способности, ранее считавшиеся чисто человеческой прерогативой.
Отличие ИИ от нейросетей и машинного обучения
Нейросети представляют собой математическую модель, компьютерный алгоритм, работа которого основана на множестве искусственных нейронов. Суть этой системы в том, что ее не нужно заранее программировать. Она моделирует работу нейронов человеческого мозга, проводит элементарные вычисления и обучается на основании предыдущего опыта, но это не соотносимо с ИИ.
Искусственный интеллект, как мы помним, является свойством сложных систем выполнять задачи, обычно свойственные человеку. К ИИ часто относят узкоспециализированные компьютерные программы, также различные научно-технологические методы и решения. ИИ в своей работе имитирует человеческий мозг, при этом основывается на прочих логических и математических алгоритмах или инструментах, в том числе нейронных сетях.
Под машинным обучением понимают использование различных технологий для самообучающихся программ. Соответственно, это одно из многочисленных направлений ИИ. Системы, основанные на машинном обучении, получают базовые данные, анализируют их, затем на основе полученных выводов находят закономерности в сложных задачах со множеством параметров и дают точные ответы. Один из наиболее распространенных вариантов организации машинного обучения – применение нейросетей.
Если сравнивать с человеком, то ИИ подобен головному мозгу, машинное обучение – это один из многочисленных способов обработки поступающих данных и решения назревающих задач, а нейросети соответствуют объединению более мелких, базовых элементов мозга – нейронов.
Разница между искусственным и естественным интеллектом
Сравнивать искусственный и естественный интеллект можно лишь по некоторым общим параметрам. Например, человеческий мозг и компьютер работают по примерно схожему принципу, включающему четыре этапа – кодирование, хранение данных, анализ и предоставление результатов. И естественный, и искусственный разум склонны к самообучению, они решают те или иные задачи и проблемы, используя специальные алгоритмы.
Помимо общих умственных способностей к рассуждению, обучению и решению проблем, человеческое мышление также имеет эмоциональную окраску и сильно зависит от влияния социума. Искусственный интеллект не имеет никакого эмоционального характера и не ориентирован социально.
Если говорить об IQ – большинство ученых склонны считать, что сей параметр оценки никак не связан с искусственным интеллектом. С одной стороны, это действительно так, ведь стандартные IQ-тесты направлены на измерение «качества» человеческого мышления и связаны с развитием интеллекта на разных возрастных этапах.
С другой стороны, для ИИ создан собственный «IQ-тест», названный в честь Тьюринга. Он помогает определить, насколько хорошо машина обучилась и способна ли она уподобиться в общении человеку. Это своего рода планка для ИИ, установленная людьми. А ведь все больше ученых склоняется к тому, что скоро компьютеры обгонят человечество по всем параметрам… Развитие технологий идет по непредсказуемому сценарию, и вполне допустимо, что так и будет.
Применение ИИ в современной жизни

В зависимости от области и обширности сферы применения, выделяют два вида ИИ – Weak AI, называемый еще «слабым», и Strong AI, «сильный». В первом случае перед системой ставят узкоспециализированные задачи – диагностика в медицине, управление роботами, работа на базе электронных торговых платформ. Во втором же подразумевается решение глобальных задач.
Так, одна из наиболее популярных сфер применения ИИ – это Big Data в коммерции. Крупные торговые площадки используют подобные технологии для исследования потребительского поведения. Компания «Яндекс» вообще создает с их помощью музыку. В некоторые мобильные приложения встроены голосовые помощники вроде Siri, Алисы или Cortana. Они упрощают процесс навигации и совершения покупок в сервисе. И не стоит забывать про программы с нейросетями, обрабатывающими фото и видео.
ИИ также внедряют в производственные процессы для фиксации действий работников. Не обошлось и без внедрения новых технологических решений в транспортной сфере. Так, искусственный интеллект мониторит состояние на дорогах, фиксирует пробки, обнаруживает разные объекты в неположенных местах. А про автономное (беспилотное) вождение и так постоянно говорят…
Люксовые бренды внедряют ИИ в свои системы для анализа потребностей клиентов. Стремительно развивается использование подобных систем в системах здравоохранения, в основном при диагностике заболеваний, разработке лекарств, создании медицинских страховок, проведении клинических исследований и так далее.
Перечислить разом все области, в которых задействован искусственный интеллект, практически нереально. На данный момент он затрагивает все больше самых разных сфер. И причин на то немало – та же автоматизация производственных процессов, стремительный рост информационного оборота и инвестиций в эту сферу, даже социальное давление.
Влияние на различные области

ИИ все больше проникает в экономическую сферу, и, по некоторым прогнозам, это позволит увеличить объем глобального рынка на 15,7 трлн долларов к 2030 году. Лидирующую позицию в освоении сей технологии занимают США и Китай, однако некоторые развитые страны вроде Канады, Сингапура, Германии и Японии не отстают.
Искусственный интеллект может оказать существенное влияние на рынок труда. Это может привести к массовому увольнению рабочего персонала из-за автоматизации большинства процессов. Ну и росту востребованности разработчиков, конечно.
Перспективы развития искусственного интеллекта
Современные компьютеры приобретают все больше знаний и «умений». Скептики же утверждают, что все возможности ИИ – не более чем компьютерная программа, а не пример самообучения. Однако это не мешает технологии широко распространяться в самых различных сферах и открывать невиданные ранее потенциалы для развития. Со временем компьютеры будут становиться все мощнее, а ИИ еще быстрее совершенствоваться в своем развитии.
Заключение
Не так давно, казалось бы, ученые ввели понятие «искусственный интеллект», а чуть больше полвека спустя технология уже находит широкий спрос в самых различных сферах. Сейчас искусственный разум, можно сказать, находится в шаговой доступности для любого человека – компьютер и ноутбук, смартфон и электронные часы, даже многие простейшие приложения работают именно с его помощью. ИИ в самых разных своих проявлениях проник во многие сферы человеческой жизни и прочно обосновался в них.
Возможно, страхи ученых вполне обоснованы? Как знать 🙂
Всё, что вам нужно знать об ИИ — за несколько минут

Приветствую читателей Хабра. Вашему вниманию предлагается перевод статьи «Everything you need to know about AI — in under 8 minutes.». Содержание направлено на людей, не знакомых со сферой ИИ и желающих получить о ней общее представление, чтобы затем, возможно, углубиться в какую-либо конкретную его отрасль.
Знать понемногу обо всё иногда (по крайней мере, для новичков, пытающихся сориентироваться в популярных технических направлениях) бывает полезнее, чем знать много о чём-то одном.
Многие люди думают, что немного знакомы с ИИ. Но эта область настолько молода и растёт так быстро, что прорывы совершаются чуть ли не каждый день. В этой научной области предстоит открыть настолько многое, что специалисты из других областей могут быстро влиться в исследования ИИ и достичь значимых результатов.
Эта статья — как раз для них. Я поставил себе целью создать короткий справочный материал, который позволит технически образованным людям быстро разобраться с терминологией и средствами, используемыми для разработки ИИ. Я надеюсь, что этот материал окажется полезным большинству интересующихся ИИ людей, не являющихся специалистами в этой области.
Введение
Искусственный интеллект (ИИ), машинное обучение и нейронные сети — термины, используемые для описания мощных технологий, базирующихся на машинном обучении, способных решить множество задач из реального мира.
В то время, как размышление, принятие решений и т.п. сравнительно со способностями человеческого мозга у машин далеки от идеала (не идеальны они, разумеется, и у людей), в недавнее время было сделано несколько важных открытий в области технологий ИИ и связанных с ними алгоритмов. Важную роль играет увеличивающееся количество доступных для обучения ИИ больших выборок разнообразных данных.
Область ИИ пересекается со многими другими областями, включая математику, статистику, теорию вероятностей, физику, обработку сигналов, машинное обучение, компьютерное зрение, психологию, лингвистику и науку о мозге. Вопросы, связанные с социальной ответственностью и этикой создания ИИ притягивают интересующихся людей, занимающихся философией.
Мотивация развития технологий ИИ состоит в том, что задачи, зависящие от множества переменных факторов, требуют очень сложных решений, которые трудны к пониманию и сложно алгоритмизируются вручную.
Растут надежды корпораций, исследователей и обычных людей на машинное обучение для получения решений задач, не требующих от человека описания конкретных алгоритмов. Много внимания уделяется подходу «чёрного ящика». Программирование алгоритмов, используемых для моделирования и решения задач, связанных с большими объёмами данных, занимает у разработчиков очень много времени. Даже когда нам удаётся написать код, обрабатывающий большое количество разнообразных данных, он зачастую получается очень громоздким, трудноподдерживаемым и тяжело тестируемым (из-за необходимости даже для тестов использовать большое количество данных).
Современные технологии машинного обучения и ИИ вкупе с правильно подобранными и подготовленными «тренировочными» данными для систем могут позволить нам научить компьютеры «программировать» за нас.

Обзор
Интеллект — способность воспринимать информацию и сохранять её в качестве знания для построения адаптивного поведения в среде или контексте
Это определение интеллекта из (англоязычной) Википедии может быть применено как к органическому мозгу, так и к машине. Наличие интеллекта не предполагает наличие сознания. Это — распространённое заблуждение, принесённое в мир писателями научной фантастики.
Попробуйте поискать в интернете примеры ИИ — и вы наверняка получите хотя бы одну ссылку на IBM Watson, использующий алгоритм машинного обучения, ставший знаменитым после победы на телевикторине под названием «Jeopardy» в 2011 г. С тех пор алгоритм претерпел некоторые изменения и был использован в качестве шаблона для множества различных коммерческих приложений. Apple, Amazon и Google активно работают над созданием аналогичных систем в наших домах и карманах.
Обработка естественного языка и распознавание речи стали первыми примерами коммерческого использования машинного обучения. Вслед за ними появились задачи другие задачи автоматизации распознавания (текст, аудио, изображения, видео, лица и т.д.). Круг приложений этих технологий постоянно растёт и включает в себя беспилотные средства передвижения, медицинскую диагностику, компьютерные игры, поисковые движки, спам-фильтры, борьбу с преступностью, маркетинг, управление роботами, компьютерное зрение, перевозки, распознавание музыки и многое другое.
ИИ настолько плотно вошёл в современные используемые нами технологии, что многие даже не думают о нём как об «ИИ», то есть, не отделяют его от обычных компьютерных технологий. Спросите любого прохожего, есть ли искусственный интеллект в его смартфоне, и он, вероятно, ответит: «Нет». Но алгоритмы ИИ находятся повсюду: от предугадывания введённого текста до автоматического фокуса камеры. Многие считают, что ИИ должен появиться в будущем. Но он появился некоторое время назад и уже находится здесь.
Термин «ИИ» является довольно обобщённым. В фокусе большинства исследований сейчас находится более узкое поле нейронных сетей и глубокого обучения.
Как работает наш мозг
Человеческий мозг представляет собой сложный углеродный компьютер, выполняющий, по приблизительным оценкам, миллиард миллиардов операций в секунду (1000 петафлопс), потребляющий при этом 20 Ватт энергии. Китайский суперкомпьютер под названием «Tianhe-2» (самый быстрый в мире на момент написания статьи) выполняет 33860 триллионов операций в секунду (33.86 петафлопс) и потребляющий при этом 17600000 Ватт (17.6 Мегаватт). Нам предстоит проделать определённое количество работы перед тем, как наши кремниевые компьютеры смогут сравниться со сформировавшимися в результате эволюции углеродными.
Точное описание механизма, применяемого нашим мозгом для того, чтобы «думать» является предметом дискуссий и дальнейших исследований (лично мне нравится теория о том, что работа мозга связана с квантовыми эффектами, но это — тема для отдельной статьи). Однако, механизм работы частей мозга обычно моделируется с помощью концепции нейронов и нейронных сетей. Предполагается, что мозг содержит примерно 100 миллиардов нейронов.
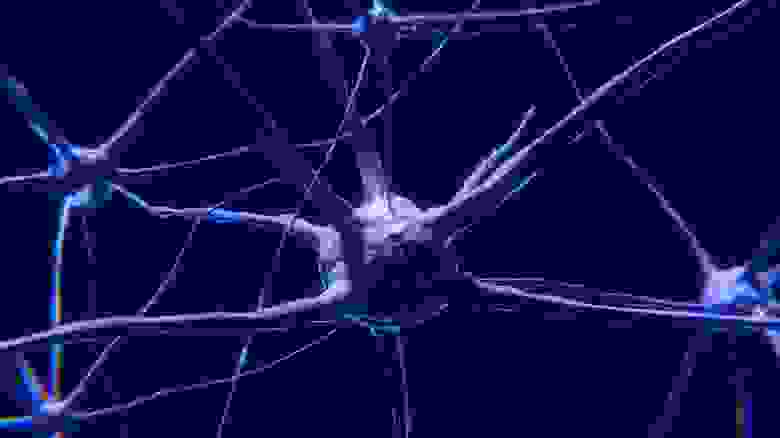
Нейроны взаимодействуют друг с другом с помощью специальных каналов, позволяющих им обмениваться информацией. Сигналы отдельных нейронов взвешиваются и комбинируются друг с другом перед тем, как активировать другие нейроны. Эта обработка передаваемых сообщений, комбинирование и активация других нейронов повторяется в различных слоях мозга. Учитывая то, что в нашем мозгу находится 100 миллиардов нейронов, совокупность взвешенных комбинаций этих сигналов устроена довольно сложно. И это ещё мягко сказано.
Но на этом всё не заканчивается. Каждый нейрон применяет функцию, или преобразование, к взвешенным входным сигналам перед тем, как проверить, достигнут ли порог его активации. Преобразование входного сигнала может быть линейным или нелинейным.
Изначально входные сигналы приходят из разнообразных источников: наших органов чувств, средств внутреннего отслеживания функционирования организма (уровня кислорода в крови, содержимого желудка и т.д.) и других. Один нейрон может получать сотни тысяч входных сигналов перед принятием решения о том, как следует реагировать.
Мышление (или обработка информации) и полученные в результате его инструкции, передаваемые нашим мышцам и другим органам являются результатом преобразования и передачи входных сигналов между нейронами из различных слоёв нейронной сети. Но нейронные сети в мозгу могут меняться и обновляться, включая изменения алгоритма взвешивания сигналов, передаваемых между нейронами. Это связано с обучением и накоплением опыта.
Эта модель человеческого мозга использовалась в качестве шаблона для воспроизведения возможностей мозга в компьютерной симуляции — искуственной нейронной сети.
Искусственные Нейронные Сети (ИНС)
Искусственные Нейронные Сети — это математические модели, созданные по аналогии с биологическими нейронными сетями. ИНС способны моделировать и обрабатывать нелинейные отношения между входными и выходными сигналами. Адаптивное взвешивание сигналов между искусственными нейронами достигается благодаря обучающемуся алгоритму, считывающему наблюдаемые данные и пытающемуся улучшить результаты их обработки.

Для улучшения работы ИНС применяются различные техники оптимизации. Оптимизация считается успешной, если ИНС может решать поставленную задачу за время, не превышающее установленные рамки (временные рамки, разумеется, варьируются от задачи к задаче).
ИНС моделируется с использованием нескольких слоёв нейронов. Структура этих слоёв называется архитектурой модели. Нейроны представляют собой отдельные вычислительные единицы, способные получать входные данные и применять к ним некоторую математическую функцию для определения того, стоит ли передавать эти данные дальше.
В простой трёхслойной модели первый слой является слоем ввода, за ним следует скрытый слой, а за ним — слой вывода. Каждый слой содержит не менее одного нейрона.
С усложнением структуры модели посредством увеличения количества слоёв и нейронов возрастают потенциал решения задач ИНС. Однако, если модель оказывается слишком «большой» для заданной задачи, её бывает невозможно оптимизировать до нужного уровня. Это явление называется переобучением (overfitting).
Архитектура, настройка и выбор алгоритмов обработки данных являются основными составляющими построения ИНС. Все эти компоненты определяют производительность и эффективность работы модели.
Модели часто характеризуются так называемой функцией активации. Она используется для преобразования взвешенных входных данных нейрона в его выходные данные (если нейрон решает передавать данные дальше, это называется его активацией). Существует множество различных преобразований, которые могут быть использованы в качестве функций активации.
ИНС являются мощным средством решения задач. Однако, хотя математическая модель небольшого количества нейронов довольно проста, модель нейронной сети при увеличении количества составляющих её частей становится довольно запутанно. Из-за этого использование ИНС иногда называют подходом «чёрного ящика». Выбор ИНС для решения задачи должен быть тщательно обдуманным, так как во многих случаях полученное итоговое решение нельзя будет разобрать на части и проанализировать, почему оно стало именно таким.

Глубокое обучение
Термин глубокое обучение используется для описания нейронных сетей и используемых в них алгоритмах, принимающих «сырые» данные (из которых требуется извлечь некоторую полезную информацию). Эти данные обрабатываются, проходя через слои нейросети, для получения нужных выходных данных.
Обучение без учителя (unsupervised learning) — область, в которой методики глубокого обучения отлично себя показывают. Правильно настроенная ИНС способна автоматически определить основные черты входных данных (будь то текст, изображения или другие данные) и получить полезный результат их обработки. Без глубокого обучения поиск важной информации зачастую ложится на плечи программиста, разрабатывающего систему их обработки. Модель глубокого обучения же самостоятельно способна найти способ обработки данных, позволяющий извлекать из них полезную информацию. Когда система проходит обучение (то есть, находит тот самый способ извлекать из входных данных полезную информацию), требования к вычислительной мощности, памяти и энергии для поддержания работы модели сокращаются.
Проще говоря, алгоритмы обучения позволяют с помощью специально подготовленных данных «натренировать» программу выполнять конкретную задачу.
Глубокое обучение применяется для решения широкого круга задач и считается одной из инновационных ИИ-технологий. Существуют также другие виды обучения, такие как обучение с учителем (supervised learning) и обучение с частичным привлечением учителя(semi-supervised learning), которые отличаются введением дополнительного контроля человека за промежуточными результатами обучения нейронной сети обработке данных (помогающего определить, в правильном ли направлении движется система).
Теневое обучение (shadow learning) — термин, используемый для описания упрощённой формы глубокого обучения, при которой поиск ключевых особенностей данных предваряется их обработкой человеком и внесением в систему специфических для сферы, к которой относятся эти данные, сведений. Такие модели бывают более «прозрачными» (в смысле получения результатов) и высокопроизводительными за счёт увеличения времени, вложенного в проектирование системы.
Базы данных в ИИ
О перспективах применения систем объектно-ориентированных баз данных и знаний в системах искусственного интеллекта
Я считаю, что практика эксплуатации реляционных систем управления базами данных выявила значительные ограничения в реляционной модели представления данных. В настоящее время назрела необходимость отказаться от реляционной модели и обратить внимание на незаслуженно забытые сетевые и объектно-ориентированные модели представления данных. Это позволит уже в ближайшее время достичь заметного успеха в применении средств искусственного интеллекта при решении актуальных проблем современного бизнеса.
Несмотря на имеющиеся достоинства, реляционная модель представления данных обладает и рядом недостатков. В случае нормализации модели предметной области БД представляет собой множество связанных друг с другом таблиц. Наряду с тривиальной необходимостью выполнять множество соединений на множестве таблиц, такая структура значительно усложняет сопровождение базы данных. При изменении бизнеса приходится заново проектировать новый вариант нормализованной базы и выкидывать труд разработчиков, затраченный на разработку предыдущей версии БД и приложений, работающих с предыдущей версией. Не спасает ситуацию и проектирование реляционной структуры таблиц, специально рассчитанной на изменения модели бизнеса в процессе эксплуатации приложения. В этом случае, разработчики реляционных БД используют три подхода.
Итак, плачевная ситуация, сложившаяся в области использования реляционных систем управления базами данных продолжает усложнятся. Мы все можем наблюдать, как производители РСУБД от отчаяния вводят в свои продукты объектные расширения (Oracle, Informix, …) и возможности по обработке XML, реализацию бизнес логики приложения на стороне СУБД средствами процедурных языков (Oracle, Microsoft, …). По сути эта ситуация говорит о поражении реляционной модели данных как универсального средства моделирования современных бизнес процессов.
Владельцы существующих систем управления реляционными базами данных, вложившие в разработку продуктов многие миллионы долларов, маркетологи, имеющие основной задачей рекламу продукта на рынке и просто наивные пользователи пытаются нас убедить в том, что развитие РМД эволюционным путем может сохранить инвестиции и решить все описанные проблемы. Так ли это?
Для ответа на этот вопрос отвлечемся от систем управления базами данных и рассмотрим моделирование бизнес-процесса, как основную задачу, которая сегодня решается с применением СУБД. Очевидно, что целью индустриализации нашего общества является замена труда человека на труд машины. Информатизация общества ведет к замене интеллекта человека на интеллект машины. Автоматизация бизнес-процессов доведенная до абсолюта предполагает полное отчуждение человека от выполнения рутинных интеллектуальных задач. В результате можно сделать вывод, что доведенная до абсолюта система моделирования бизнес-процессов должна обладать искусственным интеллектом. Внедрение такой системы должно оставить за человеком только творческие задачи, полностью автоматизировав рутинные операции по управлению современным предприятием. Такая система должна обладать знаниями и способностями, сопоставимыми с бизнес-аналитиком среднего уровня. Это означает, что система управления базой знаний (именно знаний, а не данных) должна обеспечить представление и обработку модели бизнес-процесса сопоставимой по своей сложности с моделью бизнес-процесса, используемой сознанием человека. Системы, которые не соответствуют этому требованию, рано или поздно окажутся устаревшими и будут заменены на системы, обладающие искусственным интеллектом. Да, это перспектива не самого ближайшего времени. Но бизнес уже сейчас делает вызов разработчикам ставя задачи, которые требуют применения средств искусственного интеллекта. Отсутствие систем ИИ в широкой эксплуатации обусловлено вовсе не отсутствием задач, требующих для своего решения моделей, основанных на ИИ. Задачи по автоматизации бизнеса поставлены не вчера, и не позавчера, они поставлены еще в эпоху появления первых счет и арифмометров. Текущий уровень разработок информационных систем определяется текущем уровнем достижений в области моделирования и обработки бизнес данных и бизнес знаний. Наши пользователи получают вовсе не то что им надо, а всего лишь то, что мы в состоянии разработать, пользуясь модными средствами разработки.
Какая модель представления данных, известная на сегодняшний день, более адекватно отражает модель мира и реальности, в которой мы все живем? Я считаю, что это сетевая объектно-ориентированная модель представления данных и знаний. Современные успехи в области объектно-ориентированных методов разработки программного обеспечения также подтверждают эту мысль.
Недостатками объектных баз данных обычно считают трудности в реализации объектных представлений, трудности в реализации незапланированных запросов к базе и необходимость итерации по коллекциям объектов при поиске объектов по значениям их атрибутов. Если сравнивать чистую РМД и чистую ОМД, то можно согласится, что представления в РМД можно рассматривать как отношения, однако представления объектов в ОМД рассматривать как объекты тяжелее. В практических случаях, в таблицы РБД вводят суррогатные ключи для обеспечения требования «нет сущности без идентификатора». В этом случае РБД обретает трудности полностью эквивалентные ОБД в реализации представлений. Об этом, например, свидетельствуют множество ограничений при реализации updatable views. Следовательно, на практике, с точки зрения реализации представлений ОБД и РБД можно считать практически равноправными. Трудности реализации незапланированных запросов к базе объектов являются вымышленными. Незапланированные запросы к дереву объектов можно реализовать, например, на основе языков OQL или XPath. Для оптимизации поиска объектов по значению их атрибутов в ОБД, так же как и в РБД возможно создание и использование индексов. Итак, с точки зрения рассмотренных возможностей ОМД не уступает РМД.
Разработанная система обладает следующими возможностями:
Применение СООБЗ не накладывает никаких ограничений на используемую бизнес логику объекта или математическую модель нейрона, которую можно реализовать как методы объектов, находящихся в СООБЗ.
Объектно-ориентированная модель представления данных, используемая в Cerebrum, свободна от перечисленных ранее недостатков РБД. Возможность моделировать сложноструктурированные объекты позволяет объединять несколько экземпляров объектов в единое целое, называемое компонентом. В отличие от РМД, такой компонент может храниться в базе данных как единое целое. Это значительно увеличивает эффективность работы системы. Но не это главное. Так как компонент представляет собой агрегацию нескольких экземпляров объектов, в объектной модели, возможно динамически изменять внутреннюю структуру компонента, не затрагивая при этом структуры других компонентов того же типа, хранящихся в БД. Объектная модель позволяет реализовывать наследование классов и множественное наследование интерфейсов. В отличие от рассмотренного ранее первого подхода, ООБД позволяет изменять внутреннюю структуру отдельно взятого компонента, не влияя на другие компоненты, находящиеся в БД. Это решает проблему представления и обработки версий объектов. Наличие развитой информации о типах позволяет обращаться к внутренней структуре такого компонента, так же как и к отдельным полям таблицы в случае РМД. В отличие от второго подхода, сохраняя возможность работать с внутренней структурой компонента, ООБД позволяют избавиться от разрастания размера индексов и необходимости применять соединения при доступе к атрибутам компонента. Так же исчезают проблемы потери типа атрибутов и трудности при реализации коллекций объектов. Объектная модель свободна от ограничений третьего подхода на количество атрибутов одного типа. Дополнительными достоинством объектной модели представления данных является возможность трактовать любую представляемую в БД сущность как объект. Это позволяет сохранять в атрибутах объекта не только простые значения, но и компоненты со сложной внутренней структурой.
Уже сейчас результаты теоретических исследований и практических экспериментов позволяют успешно реализовать сетевую объектно-ориентированную систему управления знаниями. Такая система окажется полезна не только в решении перспективных задач, но и при решении насущных проблем бизнеса, традиционно решаемых с использованием РСУБД. Я считаю, что, учитывая необходимость перехода к системам, основанным на ИИ, требуется отказаться от догмы о превосходстве реляционной модели данных и сосредоточить основные усилия в исследованиях и разработках альтернативных моделей. Я надеюсь, что сетевая объектно-ориентированная база знаний Cerebrum позволит определить путь дальнейшего развития систем управления данными и знаниями и приблизит создание промышленных систем с искусственным интеллектом.
Как ты считаеешь, будет ли теория про базы данных в ии улучшена в обозримом будующем? Надеюсь, что теперь ты понял что такое базы данных в ии и для чего все это нужно, а если не понял, или есть замечания, то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории Представление и использование знаний