кафка что такое топик
PVbase: compacted topic в Apache Kafka
Подумайте о проблеме, которую вы можете решить с помощью Big Data, и задайте себе вопрос: «Что будет, если мы захотим увеличить масштаб в 100 000 раз?» Ответ прост: producer продолжит закачивать сообщения, в итоге на диске закончится место для их хранения.

Log Compaction (сжатие журнала) – стратегия, с помощью которой вы можете решить эту проблему в Apache Kafka – программном брокере сообщений, используемом для ведения журналов событий, чтения данных в непрерывном режиме с периферийных устройств, сбора информации о поведении посетителей на сайте. Большинство систем, использующих Kafka, являются распределёнными и обрабатывают большие объёмы сообщений в реальном времени.
Здесь я постараюсь описать некоторые нюансы работы compacted topic. Если вы хотите разобраться с механизмом log compaction, эта статья для вас.
Суть сжатия журнала заключается в выборочном удалении записей, в которых у нас есть последнее обновление с тем же первичным ключом.
Для простоты понимания процесса приведём такую аналогию из жизни: допустим, некий человек (Иван Иванович) каждый день смотрит на градусник и вносит записи о температуре в электронный журнал (в раздел «Температура воздуха»):
2 ноября 2021, 14:40
3 ноября 2021, 10:10
Другие люди с некой периодичностью смотрят эти записи и используют их в своей деятельности. Причём в практическом смысле их интересует только самая последняя температура, данные по прошедшим дням значения не имеют.
Со временем журнал может быть переполнен ненужными записями, поэтому раз в неделю приходит Василий Петрович и чистит его, удаляя все сообщения и оставляя там только последнюю запись (потому что остальные не имеют смысла):
Таким образом, в приведённом выше описании по терминологии Kafka:
Ключ (key): Иван Иванович;
Значение (value): +10 градусов;
Метка времени (timestamp): 4 ноября 2021, 15:30;
Топик (topic): способ группировки потоков сообщений по категориям [4] – раздел журнала «Температура воздуха»;
Раздел (partition): последовательность сообщений топика, которые упорядочены в порядке их поступления [4];
Зная всё это, сообщения от Ивана Ивановича можно представить в следующем виде:
ЖУРНАЛ СООБЩЕНИЙ
Топик (topic): раздел журнала «Температура воздуха»
Раздел (partition)
Ключ (key)
Значение (value)
Метка времени (timestamp)
2 ноября 2021, 14:40
3 ноября 2021, 10:10
4 ноября 2021, 15:30
Cтратегия Log Compaction гарантирует, что Kafka всегда будет сохранять по крайней мере последнее известное значение для каждого ключа сообщения в журнале для одного раздела топика. В основном он используется для таких сценариев, как восстановление к состоянию до сбоя приложения или системы, а также при перезагрузке кеша после перезапуска приложения. Проще говоря, Apache Kafka будет хранить последнюю версию записи и удалять старые версии с тем же ключом.
Сжатие журнала Kafka позволяет потребителям (consumer-ам) восстановить своё состояние из записи compacted topic. Этот процесс не изменит порядок сообщений, но удалит некоторые из них. Кроме того, смещение (offset) раздела для сообщения не изменится. Журнал данных состоит из головы (head) и хвоста (tail). Каждое новое сообщение добавляется в конец head. Все записи log compaction находятся в хвосте уплотнённого блока.
 Рис. 1. Архитектура Kafka – смещение разделов
Рис. 1. Архитектура Kafka – смещение разделов
Базовый алгоритм удаления неактуальных данных в топиках основан на следующих свойствах:
cleanup.policy=delete – включает механизм удаления неактуальных сообщений;
retention.bytes – определяет размер партиции, после превышения которого следует начать удалять сообщения;
retention.ms – определяет максимальный возраст сообщения, после превышения которого следует его удалить.
Важная особенность, которую все упускают! Брокер Kafka хранит сообщения в сегментах. Они будут удаляться только тогда, когда все сообщения в конкретном сегменте соответствуют критериям retention policy.
Но если установить cleanup.policy=compact, то стратегия будет compacted topic. Чтобы понять механику, определим важные термины:
LogCleaner – пул потоков, которые осуществляют сжатие лога;
LogTail – часть лога, над которой уже была произведена процедура сжатия;
LogHead – часть лога, над которой процедура сжатия не производилась.
Сам процесс будет выглядеть следующим образом:
LogCleaner определяет лог с наибольшим отношением logHead/logTail.
Он определяет все offset’ы по каждому ключу в logHead.
Копирует самый старый сегмент, удаляя сообщения, ключи которых присутствуют дальше в логе.
Подменяет оригинальный сегмент на сжатый.
Важные параметры настройки logCleaner:
log.cleanup.policy=compact – основное свойство, которое включает log compaction;
log.cleaner.max.compaction.lag.ms – время жизни сообщения, ключ которого существует дальше по логу;
log.cleaner.threads – кол-во потоков logCleaner.
Эта стратегия удаляет не только повторяющиеся записи, но также ключи с нулевым значением.
Детали алгоритма работы
Базовый алгоритм удаления неактуальных данных в топиĸах основан на следующих свойствах:
cleanup.policy=delete – включает механизм удаления неактуальных сообщений;
retention.bytes – определяет размер раздела, после превышения которого следует начать удалять сообщения;
retention.ms – определяет максимальный возраст сообщения, после превышения которого нужно его удалить.
Посмотрим на живом примере, ĸаĸ работает log compaction.
Сĸачав последнюю версию Apache Kafka (в моём случае 2.7.0), поднимем zookeeper и броĸера с default-настройĸами:
Затем создадим топиĸ:
В оĸне producer’а напишем сообщения:
В оĸне consumer’a вы найдёте все те же сообщения. Теперь через 60–90 секунд перезапустите consoleconsumer, и вы увидите:
Сжатые разделы требуют ресурсов памяти и ЦП ваших брокеров. Для успешного завершения сжатия журналов нужна как куча (память), так и циклы ЦП на брокерах, а неудачное сжатие журналов подвергает брокеров риску из-за неограниченного роста раздела.
Вы можете настроить log.cleaner.dedupe.buffer.size и log.cleaner.threads на своих брокерах, но имейте в виду, что эти значения влияют на использование кучи. Если брокер выдаст исключение OutOfMemoryError, он отключится и потенциально может потерять данные.
Размер буфера и количество потоков будут зависеть как от количества очищаемых разделов темы, так и от скорости передачи данных и размера ключа сообщений в этих разделах.
Сжатие журнала – хороший вариант для сценариев кеширования, из которых вы можете просто прочитать последнее состояние compacted topic’а.
Практический взгляд на хранение в Kafka

Оригинал статьи на английском
Kafka повсюду. Где есть микросервисы и распределенные вычисления, а они сейчас популярны, там почти наверняка есть и Kafka. В статье я попытаюсь объяснить, как в Kafka работает механизм хранения.
Я, конечно, постарался не усложнять, но копать будем глубоко, поэтому какое-то базовое представление о Kafka не помешает. Иначе не все будет понятно. В общем, продолжайте читать на свой страх и риск.
Обычно считается, что Kafka — это распределенная и реплицированная очередь сообщений. С технической точки зрения все верно, но термин очередь сообщений не все понимают одинаково. Я предпочитаю другое определение: распределенный и реплицированный журнал коммитов. Эта формулировка кажется более точной, ведь мы все прекрасно знаем, как журналы записываются на диск. Просто в этом случае на диск попадают сообщения, отправленные в Kafka.

Применительно к хранению в Kafka используется два термина: партиции и топики. Партиции — это единицы хранения сообщений, а топики — что-то вроде контейнеров, в которых эти партиции находятся.
С основной теорией мы определились, давайте перейдем к практике.
Я создам в Kafka топик с тремя партициями. Если хотите повторять за мной, вот как выглядит команда для локальной настройки Kafka в Windows.
В каталоге журналов Kafka создано три каталога:
$ tree freblogg*
freblogg-0
|— 00000000000000000000.index
|— 00000000000000000000.log
|— 00000000000000000000.timeindex
`— leader-epoch-checkpoint
freblogg-1
|— 00000000000000000000.index
|— 00000000000000000000.log
|— 00000000000000000000.timeindex
`— leader-epoch-checkpoint
freblogg-2
|— 00000000000000000000.index
|— 00000000000000000000.log
|— 00000000000000000000.timeindex
`— leader-epoch-checkpoint
Мы создали в топике три партиции, и у каждой — свой каталог в файловой системе. Еще тут есть несколько файлов (index, log и т д.), но о них чуть позже.
Обратите внимание, что в Kafka топик — это логическое объединение, а партиция — фактическая единица хранения. То, что физически хранится на диске. Как устроены партиции?
Партиции
В теории партиция — это неизменяемая коллекция (или последовательность) сообщений. Мы можем добавлять сообщения в партицию, но не можем удалять. И под «мы» я подразумеваю продюсеров в Kafka. Продюсер не может удалять сообщения из топика.
Сейчас мы отправим в топик пару сообщений, но сначала обратите внимание на размер файлов в папках партиций.
Как видите, файлы index вместе весят 20 МБ, а файл log совершенно пустой. В папках freblogg-1 и freblogg-2 то же самое.
Давайте отправим сообщения через console producer и посмотрим, что будет:
Я отправил два сообщения — сначала ввел стандартное «Hello World», а потом нажал на Enter, и это второе сообщение. Еще раз посмотрим на размеры файлов:
freblogg-1:
total 21M
— freblogg 197121 10M Aug 5 08:26 00000000000000000000.index
— freblogg 197121 68 Aug 5 10:15 00000000000000000000.log
— freblogg 197121 10M Aug 5 08:26 00000000000000000000.timeindex
— freblogg 197121 11 Aug 5 10:15 leader-epoch-checkpoint
freblogg-2:
total 21M
— freblogg 197121 10M Aug 5 08:26 00000000000000000000.index
— freblogg 197121 79 Aug 5 09:59 00000000000000000000.log
— freblogg 197121 10M Aug 5 08:26 00000000000000000000.timeindex
— freblogg 197121 11 Aug 5 09:59 leader-epoch-checkpoint
Два сообщения заняли две партиции, и файлы log в них теперь имеют размер. Это потому, что сообщения в партиции хранятся в файле xxxx.log. Давайте заглянем в файл log и убедимся, что сообщение и правда там.
Файлы с форматом log не очень удобно читать, но мы все же видим в конце «Hello World», то есть файл обновился, когда мы отправили сообщение в топик. Второе сообщение мы отправили в другую партицию.
Обратите внимание, что первое сообщение попало в третью партицию (freblogg-2), а второе — во вторую (freblogg-1). Для первого сообщения Kafka выбирает партицию произвольно, а следующие просто распределяет по кругу (round-robin). Если мы отправим третье сообщение, Kafka запишет его во freblogg-0 и дальше будет придерживаться этого порядка. Мы можем и сами выбирать партицию, указав ключ. Kafka хранит все сообщения с одним ключом в одной и той же партиции.
Каждому новому сообщению в партиции присваивается Id на 1 больше предыдущего. Этот Id еще называют смещением (offset). У первого сообщения смещение 0, у второго — 1 и т. д., каждое следующее всегда на 1 больше предыдущего.

Давайте используем инструмент Kafka, чтобы понять, что это за странные символы в файле log. Нам они кажутся бессмысленными, но для Kafka это метаданные каждого сообщения в очереди. Выполним команду:
umping logs\freblogg-2\00000000000000000000.log
Starting offset: 0
(Я удалил из выходных данных кое-что лишнее.)
Здесь мы видим смещение, время создания, размер ключа и значения, а еще само сообщение (payload).
Надо понимать, что партиция привязана к брокеру. Если у нас, допустим, три брокера, а папка freblogg-0 существует в broker-1, в других брокерах ее не будет. У одного топика могут быть партиции в нескольких брокерах, но одна партиция всегда существует в одном брокере Kafka (если установлен коэффициент репликации по умолчанию 1, но об этом чуть позже).

Сегменты
Что это за файлы index и log в каталоге партиции? Партиция, может, и единица хранения в Kafka, но не минимальная. Каждая партиция разделена на сегменты, то есть коллекции сообщений. Kafka не хранит все сообщения партиции в одном файле (как в файле лога), а разделяет их на сегменты. Это дает несколько преимуществ. (Разделяй и властвуй, как говорится.)
Главное — это упрощает стирание данных. Я уже говорил, что сами мы не можем удалить сообщение из партиции, но Kafka может это сделать на основе политики хранения для топика. Удалить сегмент проще, чем часть файла, особенно когда продюсер отправляет в него данные.
Нули (00000000000000000000) в файлах log и index в каждой папке партиции — это имя сегмента. У файла сегмента есть файлы segment.log, segment.index и segment.timeindex.
Kafka всегда записывает сообщения в файлы сегментов в рамках партиции, причем у нас всегда есть активный сегмент для записи. Когда Kafka достигает лимита по размеру сегмента, создается новый файл сегмента, который станет активным.
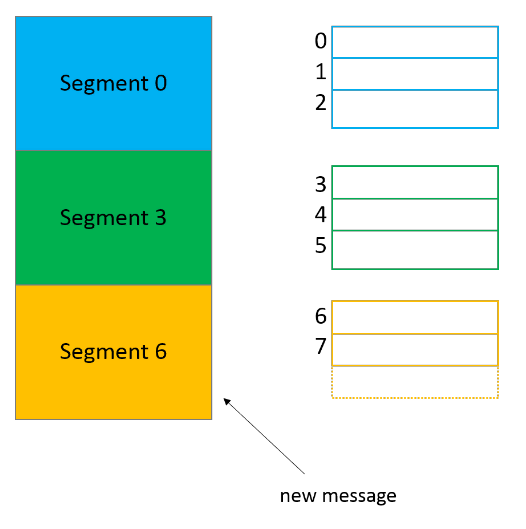
В имени каждого файла сегмента отражается смещение от первого сообщения. На картинке выше в сегменте 0 содержатся сообщения со смещением от 0 до 2, в сегменте 3 — от 3 до 5, и так далее. Последний сегмент, шестой, сейчас активен.
freblogg-1:
total 21M
— freblogg 197121 10M Aug 5 08:26 00000000000000000000.index
— freblogg 197121 68 Aug 5 10:15 00000000000000000000.log
— freblogg 197121 10M Aug 5 08:26 00000000000000000000.timeindex
— freblogg 197121 11 Aug 5 10:15 leader-epoch-checkpoint
freblogg-2:
total 21M
— freblogg 197121 10M Aug 5 08:26 00000000000000000000.index
— freblogg 197121 79 Aug 5 09:59 00000000000000000000.log
— freblogg 197121 10M Aug 5 08:26 00000000000000000000.timeindex
— freblogg 197121 11 Aug 5 09:59 leader-epoch-checkpoint
У нас всего по одному сегменту в каждой партиции, поэтому они называются 00000000000000000000. Раз других файлов сегментов нет, сегмент 00000000000000000000 и будет активным.
По умолчанию сегменту выдается целый гигабайт, но представим, что мы изменили параметры, и теперь в каждый сегмент помещается только три сообщения. Посмотрим, что получится.
Допустим, мы отправили в партицию freblogg-2 три сообщения, и она выглядит так:

Три сообщения — это наш лимит. На следующем сообщении Kafka автоматически закроет текущий сегмент, создаст новый, сделает его активным и сохранит новое сообщение в файле log этого сегмента. (Я не показываю предыдущие нули, чтобы было проще воспринять).
freblogg-2
|— 00.index
|— 00.log
|— 00.timeindex
|— 03.index
|— 03.log
|— 03.timeindex
`—
Файл index для файла log, который я приводил в кратком отступлении, будет выглядеть как-то так:
Если нужно прочитать сообщение со смещением 1, мы ищем его в файле index и видим, что его положение — 79. Переходим к положению 79 в файле log и читаем. Это довольно эффективный способ — мы быстро находим нужное смещение в уже отсортированном файле index с помощью бинарного поиска.
Параллелизм в партициях
Чтобы гарантировать порядок чтения сообщений из партиции, Kafka дает доступ к партиции только одному консюмеру (из группы консюмеров). Если партиция получает сообщения a, f и k, консюмер читает их в том же порядке: a, f и k. Это важно, ведь порядок потребления сообщений на уровне топика не гарантирован, если у вас несколько партиций.
Если консюмеров будет больше, параллелизм не увеличится. Нужно больше партиций. Чтобы два консюмера параллельно считывали данные из топика, нужно создать две партиции — по одной на каждого. Партиции в одном топике могут находиться в разных брокерах, поэтому два консюмера топика могут считывать данные из двух разных брокеров.
Топики
Наконец, переходим к топикам. Мы уже кое-что знаем о них. Главное, что нужно знать: топик — это просто логическое объединение нескольких партиций.
Топик может быть распределен по нескольким брокерам через партиции, но каждая партиция находится только в одном брокере. У каждого топика есть уникальное имя, от которого зависят имена партиций.
Репликация
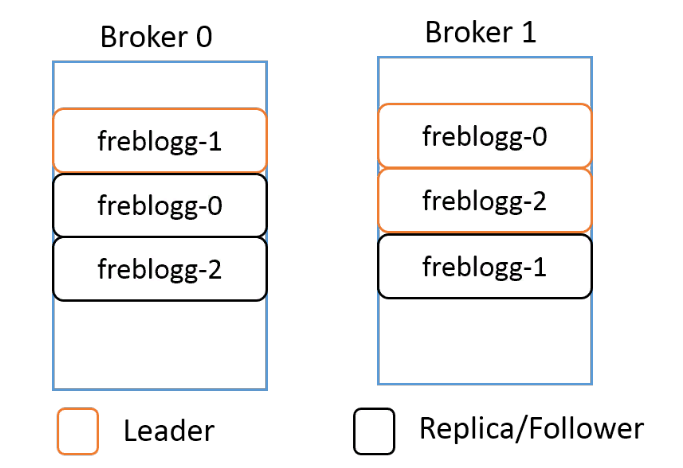
Как работает репликация? Создавая топик в Kafka, мы указываем для него коэффициент репликации — replication-factor. Допустим, у нас два брокера и мы устанавливаем replication-factor 2. Теперь Kafka попытается всегда создавать бэкап, или реплику, для каждой партиции в топике. Kafka распределяет партиции примерно так же, как HDFS распределяет блоки данных по нодам.
Допустим, для топика freblogg мы установили коэффициент репликации 2. Мы получим примерно такое распределение партиций:
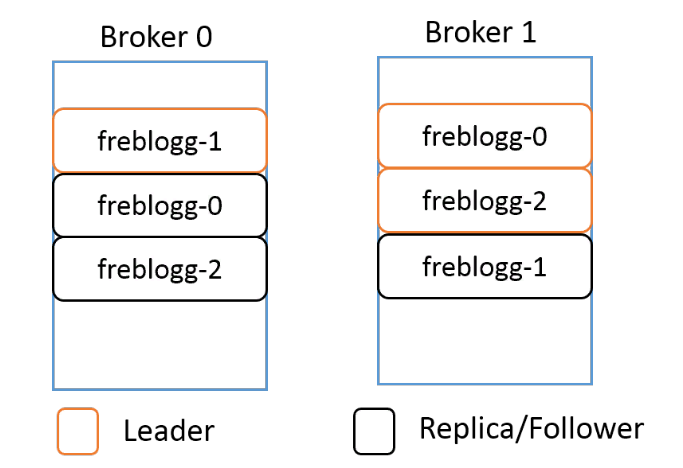
Даже если реплицированная партиция находится в другом брокере, Kafka не разрешает ее читать, потому что в каждом наборе партиций есть LEADER, то есть лидер, и FOLLOWERS — ведомые, которые остаются в резерве. Ведомые периодически синхронизируются с лидером и ждут своего звездного часа. Когда лидер выйдет из строя, один из in-sync ведомых будет выбран новым лидером, и вы будете получать данные из этой партиции.
Лидер и ведомый одной партиции всегда находятся в разных брокерах. Думаю, не нужно объяснять, почему.
Мы подошли к концу этой длинной статьи. Если вы добрались до этого места — поздравляю. Теперь вы знаете почти все о хранении данных в Kafka. Давайте повторим, чтобы ничего не забыть.
Итоги
Apache Kafka – мой конспект
Это мой конспект, в котором коротко и по сути затрону такие понятия Kafka как:
— Тема (Topic)
— Подписчики (consumer)
— Издатель (producer)
— Группа (group), раздел (partition)
— Потоки (streams)
Kafka — основное
При изучении Kafka возникали вопросы, ответы на которые мне приходилось эксперементально получать на примерах, вот это и изложено в этом конспекте. Как стартовать и с чего начать я дам одну из ссылок ниже в материалах.
Apache Kafka – диспетчер сообщений на Java платформе. В Kafka есть тема сообщения в которую издатели пишут сообщения и есть подписчики в темах, которые читают эти сообщения, все сообщения в процессе диспетчеризации пишутся на диск и не зависит от потребителей.
В состав Kafka входят набор утилит по созданию тем, разделов, готовые издатели, подписчики для примеров и др. Для работы Kafka необходим координатор «ZooKeeper», поэтому вначале стартуем ZooKeeper (zkServer.cmd) затем сервер Kafka (kafka-server-start.bat), командные файлы находятся в соответствующих папках bin, там же и утилиты.
Создадим тему Kafka утилитой, ходящей в состав
здесь указываем сервер zookeeper, replication-factor это количество реплик журнала сообщений, partitions – количество разделов в теме (об этом ниже) и собственно сама тема – “out-topic”.
Для простого тестирования можно использовать входящие в состав готовые приложения «kafka-console-consumer» и «kafka-console-producer», но я сделаю свои. Подписчики на практике объединяют в группы, это позволит разным приложениям читать сообщения из темы параллельно.

Для каждого приложения будет организованна своя очередь, читая из которой оно выполняет перемещения указателя последнего прочитанного сообщения (offset), это называется фиксацией (commit) чтения. И так если издатель отправит сообщение в тему, то оно будет гарантированно прочитано получателем этой темы если он запущен или, как только он подключится. Причем если есть разные клиенты (client.id), которые читают из одной темы, но в разных группах, то сообщения они получат не зависимо друг от друга и в то время, когда будут готовы.
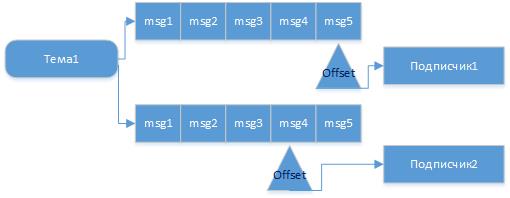
Так можно представить последователь сообщений и независимое чтение их потребителями из одной темы.
Но есть ситуация, когда сообщения в тему могут начать поступать быстрее чем уходить, т.е. потребители обрабатывают их дольше. Для этого в теме можно предусмотреть разделы (partitions) и запускать потребителей в одной группе для этой темы.

Тогда произойдет распределение нагрузки и не все сообщения в теме и группе пойдут через одного потребителя. И тогда уже будет выбрана стратегия, как распределять сообщения по разделам. Есть несколько стратегий: round-robin – это по кругу, по хэш значению ключа, или явное указание номера раздела куда писать. Подписчики в этом случае распределяются равномерно по разделам. Если, например, подписчиков будет в группе будет больше чем разделов, то кто-то не получит сообщения. Таким образом разделы делаются для улучшения масштабируемости.
Например после создания темы с одним разделом я изменил на два раздела.
my_kafka_run.cmd com.home.SimpleProducer out-topic (издатель)
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup01 client01 (первый подписчик)
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup01 client02 (второй подписчик)
Начав вводить в издателе пары ключ: значение можно наблюдать кто их получает. Так, например, по стратегии распределения по хэшу ключа сообщение m:1 попало клиенту client01

а сообщение n:1 клиенту client02

Если начну вводить без указания пар ключ: значение (такую возможность сделал в издателе), будет выбрана стратегия по кругу. Первое сообщение «m» попало client01, а уже втрое client02.
И еще вариант с указанием раздела, например в таком формате key:value:partition

Ранее в стратегии по хэш, m:1 уходил другому клиенту (client01), теперь при явном указании раздела (№1, нумеруются с 0) — к client02.
Если запустить подписчика с другим именем группы testGroup02 и для той же темы, то сообщения будут уходить параллельно и независимо подписчикам, т.е. если первый прочитал, а второй не был активен, то он прочитает, как только станет активен.

Можно посмотреть описания групп, темы соответственно:


Для запуска своих программ я сделал командный файл — my_kafka_run.cmd
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup02 client01
Kafka Streams
Итак, потоки в Kafka это последовательность событий, которые получают из темы, над которой можно выполнять определенные операции, трансформации и затем результат отдать далее, например, в другую тему или сохранить в БД, в общем куда угодно. Операции могут быть как например фильтрации (filter), преобразования (map), так и агрегации (count, sum, avg). Для этого есть соответствующие классы KStream, KTable, где KTable можно представить как таблицу с текущими агрегированными значениями которые постоянно обновляются по мере поступления новых сообщений в тему. Как это происходит?
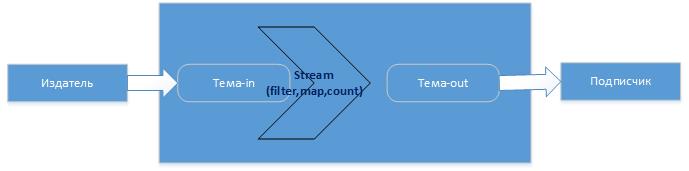
Например, издатель пишет в тему события (сообщения), Kafka все сообщения сохраняет в журнале сообщений, который имеет политику хранения (Retention Policy), например 7 дней. Например события изменения котировки это поток, далее хотим узнать среднее значение, тогда создадим Stream который возьмет историю из журнала и посчитает среднее, где ключом будет акция, а значением – среднее (это уже таблица с состоянием). Тут есть особенность – операции агрегирования в отличии от операций, например, фильтрации, сохраняют состояние. Поэтому вновь поступающие сообщения (события) в тему, будут подвержены вычислению, а результат будет сохраняться (state store), далее вновь поступающие будут писаться в журнал, Stream их будет обрабатывать, добавлять изменения к уже сохраненному состоянию. Операции фильтрации не требуют сохранения состояния. И тут тоже stream будет делать это не зависимо от издателя. Например, издатель пишет сообщения, а программа — stream в это время не работает, ничего не пропадет, все сообщения будут сохранены в журнале и как только программа-stream станет активной, она сделает вычисления, сохранит состояние, выполнит смещение для прочитанных сообщений (пометит что они прочитаны) и в дальнейшем она уже к ним не вернется, более того эти сообщения уйдут из журнала (kafka-logs). Тут видимо главное, чтобы журнал (kafka-logs) и его политика хранения позволило это. По умолчанию состояние Kafka Stream хранит в RocksDB. Журнал сообщений и все с ним связанное (темы, смещения, потоки, клиенты и др.) располагается по пути указанном в параметре «log.dirs=kafka-logs» файла конфигурации «config\server.properties», там же указывается политика хранения журнала «log.retention.hours=48». Пример лога

А путь к базе с состояниями stream указывается в параметре приложения
Состояния хранятся по ИД приложениям независимо (StreamsConfig.APPLICATION_ID_CONFIG). Пример

Проверим теперь как работает Stream. Подготовим приложение Stream из примера, который есть поставке (с некоторой доработкой для эксперимента), которое считает количество одинаковых слов и приложение издатель и подписчик. Писать будет в тему in-topic
my_kafka_run.cmd com.home.SimpleProducer in-topic
my_kafka_run.cmd com.home.KafkaCountStream in-topic app_01
my_kafka_run.cmd com.home.SimpleProducer in-topic
my_kafka_run.cmd com.home.SimpleConsumer out-topic testGroup01 client01

Начинаем вводить слова и видим их подсчет с указанием какой Stream App-ID их подсчитал

Работа будет идти независимо, можно остановить Stream и продолжать писать в тему, он потом при старте посчитает. А теперь подключим второй Stream c App-ID = app_02 (это тоже приложение, но с другим ИД), он прочитает журнал (последовательность событий, которая сохраняется согласно политике Retention), подсчитает кол-во, сохранит состояние и выдаст результат. Таким образом два потока начав работать в разное время пришли к одному результату.
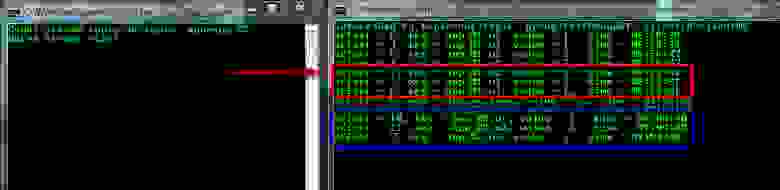
А теперь представим наш журнал устарел (Retention политика) или мы его удалили (что бывает надо делать) и подключаем третий stream с App-ID = app_03 (я для этого остановил Kafka, удалил kafka-logs и вновь стартовал) и вводим в тему новое сообщение и видим первый (app_01) поток продолжил подсчет а новый третий начал с нуля.

Если затем запустим поток app_02, то он догонит первый и они будут равны в значениях. Из примера стало понятно, как Kafka обрабатывает текущий журнал, добавляет к ранее сохраненному состоянию и так далее.
Тема Kafka очень обширна, я для себя сделал первое общее представление 🙂